
一、基于Java的map-reduce聚类算法
本次实现的简单的聚类算法,主要思想是:也是仿照K-means算法,这里的做法是提取用户点击的URL中的关键部分,比如“http://www.baidu.com”,提取出“baidu”这个关键部分作为聚类算法的关键依据,然后选出这么多搜索记录中点击数量大于20次的URL关键部分,用它和用户的UID形成一个矩阵,然后利用“余弦相似性”,来判断是否属于一个聚类。可以通过两个向量之间夹角的余弦值来判断谁和谁离的近,夹角越小,即余弦值越大,代表越相似。一开始先选择不同的k个数据作为聚类中心,然后在mapreduce的map的setup方法中先读取“聚类中心”文件中的内容,然后让进行map的数据和所有聚类中心的数据进行余弦相似度的比较,选择最相似的聚类中心,将聚类中心编号和原数据输出到reduce,再reduce中进行聚类中心的重新计算并输出保存,知道聚类中心稳定在一定范围为止,聚类结束。
这里将这次的程序分为两个部分,第一个部分是获取每个UID搜索过的URL关键词次数,但是因为所有用户合起来搜索的URL关键词数量太多,并且有的只是一个用户搜索过一次,如果全部都作为这个矩阵的列的话,那么这个矩阵不仅过于庞大,而且很多数据都是0,所以我进行了筛选,把全部搜索记录中关键词出现次数大于20次的选出来,与UID组成矩阵来进行聚类算法。通过第一个程序——selectData.java文件,产生矩阵数据,如下图所示:

当然,产生这矩阵数据之前我先生成了URL关键词与总出现次数的文件,存为dict.txt,里面的内容如下所示:
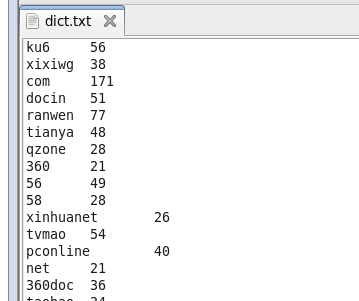
这是使用10k的数据产生的结果,筛选掉了总点击次数小于等于20次的。
得出以上数据之后,便可以运行kmeansMapReduce.java来进行聚类,第一次这里是直接选择上面reduce产生的数据矩阵中互不相同的3组数据作为初始的聚类中心,存放到centers.txt文件中,代码如下:

因为第一次mapreduce产生的数据结构是UID+数组的形式,而聚类中心需要的是后面的数组形式的数据,所以用一个split(“\t”)[1]来获取这个数据,并以此来判断是否取到不同的数据,最后将不同的这个数据写入到预设的聚类中心文件中。如下图:

产生第一次聚类中心之后,就可以在mapper的setup中预读取聚类中心的数据,存到一个ArrayList

然后在map函数中将数据与聚类中心进行比较,选出每次map的数据离哪个聚类中心的余弦值最大,context中输出聚类中心值和这个数据,代码如下:
其中,计算距离的算法是余弦相似度,方法写在kmeans.java中,这里将kmeans类作为kmeansMapReduce类的工具类来使用,算法代码如下:

由于数据格式的原因,所以将数据切割成字符串数组,然后分别计算分子、分母,求两个向量的余弦值。
然后就是在reduce中进行聚类中心的重新计算,计算的结果,也就是新的聚类中心放在newDataOne文件夹中,reduce代码如下:

生成的新的聚类中心如下图所示:

这样就完成一个基本的mapreduce,只要处理好新、旧聚类中心文件,多次这样循环处理,循环至新旧聚类中心相比较差值少于给定值便结束。这里处理好新旧聚类中心的方法是如果判断新旧聚类中心不满足结束聚类条件,那么直接将新产生的聚类中心内容拷贝并覆盖到旧的聚类中心文件中,然后删除reduce输出文件夹,然后进行新一轮的mapreduce,代码如下:

其中kmeans.copyFile()方法是处理新旧聚类中心的方法,代码如下:

deletePath()方法是删除reduce输出路径的方法,kmeans.compare()是判断是否到达聚类结束的标志,这里所用的实现思想是:将新、旧聚类中心的每一组数据都转变成double类型数据,然后将旧数据的对应坐标的数值减去新数据对应坐标的数值,取绝对值,如果值大于预设的0.0005的话说明还没有到达稳定,则稳定标志flag从初始的True变为false,只要有一个不符合就跳出全部循环,并返回flag值,代码如下:
这样经过多次循环处理,最后会得到一个符合要求的稳定的聚类中心,得到这个稳定的聚类中心之后便可以执行最后一个mapreduce程序——lastMapReduce.java,将UID数据根据得出的聚类中心归类输出,思想同上面是一样的,将UID所对应的矩阵数组与所有聚类中心比较,取距离最短的作为这个UID的聚类中心,经过map之后便能将数据归好类,然后reduce中只要按照聚好的类将value原样输出就行了。最后输出的结果是属于同一聚类的UID,以及这个UID的访问的网站次数的数组,结果如下:

可以看出,属于第一个聚类的用户UID,在所筛选出来的URL关键词的点击次数都是0次或有一个1次的,他们的矩阵全是或大部分都是0。
程序执行过程中,设定的输出如下:
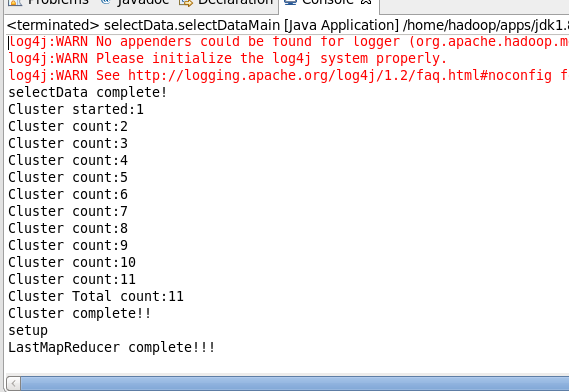
可以看到,这次聚类循环了11次才完成。
到此,本次所设计的简单入门的聚类算法到此结束,并且由于本人跑map-reduce的电脑配置不高,所以只在本地跑结果,具体代码详见附录。如有错误欢迎指正,一起学习。
聚类算法完整代码:
selectData.java
package com.zh;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class selectData {
//词表
private static HashMap<String, Integer> dictMap;
private static class selectDataMap extends Mapper<LongWritable, Text, Text, Text>{
private Set<String> dictN = new HashSet<>();
private Map<String, Integer> dict = new HashMap<>();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] str = line.split("\t");
String uid = str[1];
String url = str[5].split("/")[2].split("[.]")[1];
dictN.add(url);
if(dict.containsKey(url))dict.put(url,dict.get(url)+1);
else dict.put(url, 1);
context.write(new Text(uid), new Text(url));
}
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileWriter fw = new FileWriter(new File("../../dict.txt"));
BufferedWriter bw = new BufferedWriter(fw);
for(Iterator<String> it = dictN.iterator();it.hasNext();) {
String str = it.next();
int n = dict.get(str);
if(n>10) {
bw.write(str+"\t"+dict.get(str));
bw.newLine();
bw.flush();
}
}
bw.close();
fw.close();
}
}
private static class selectDataReduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
FileReader fr = new FileReader("../../dict.txt");
BufferedReader br = new BufferedReader(fr);
dictMap = new HashMap<>();
String line;
int count = 0;
while((line = br.readLine())!=null) {
String[] str = line.split("\t");
dictMap.put(str[0],count++);
}
br.close();
fr.close();
//FileWriter fw = new FileWriter(new File("../../test.txt"));
//BufferedWriter bw = new BufferedWriter(fw);
}
@Override
protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
int length=dictMap.size();
int[] num = new int[length];
int index = 0;
Set<String> keySet = dictMap.keySet();
// System.out.println("Key:"+key.toString());
for(Text item : value){
String str = item.toString();
// System.out.println(str);
if(keySet.contains(str)) {
index = dictMap.get(str);
// System.out.println(index);
num[index]++;
}
// System.out.println(str+" "+num[index]);
}
String line = Arrays.toString(num);
context.write(key, new Text(line));
}
}
private static class selectDataMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
Path path = new Path("../../newData");
FileSystem fs = path.getFileSystem(conf);
fs.delete(path, true);
job.setJarByClass(selectData.class);
job.setMapperClass(selectData.selectDataMap.class);
job.setReducerClass(selectData.selectDataReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, "../../Sogou/sogou.10k.utf8");
FileOutputFormat.setOutputPath(job, new Path("../../newData"));
job.waitForCompletion(true);
System.out.println("selectData complete!");
kmeansMapReduce.MainClass.main(args);
}
}
}
kmeansMapReduce.java
package com.zh;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class kmeansMapReduce {
//存放聚类中心的对象
private static ArrayList<String> centers;
static class mapper extends Mapper<LongWritable, Text, IntWritable, Text>{
@Override
protected void setup(Mapper<LongWritable, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
FileReader fr = new FileReader(new File("../../centers.txt"));
BufferedReader br = new BufferedReader(fr);
String line = null;
centers = new ArrayList<>();
while((line=br.readLine()) != null) {
centers.add(line);
}
// System.out.println("The Number Of Centers:"+centers.size());
br.close();
fr.close();
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
// System.out.println("Mapper");
IntWritable num = null;
String tmp1 = value.toString();
int centersOfNum = 0;
double dis = -1;
//System.out.println(tmp1);
for(String str:centers) {
// System.out.println(str);
double dis2 = kmeans.computerCenter(tmp1, str);
if(dis2>dis) {
//System.out.println(dis);
dis=dis2;
// System.out.println(dis);
num = new IntWritable(centersOfNum);
// if(centersOfNum>3)System.out.println("Mapper"+"\t"+centersOfNum);
}
centersOfNum++;
}
context.write(num, value);
// System.out.println("Mapper Successfully");
}
}
static class reducer extends Reducer<IntWritable, Text, IntWritable, Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> value,
Reducer<IntWritable, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
// System.out.println("reducer");
ArrayList<Double> newCenters = new ArrayList<>();
int count=0;
for(Text text:value) {
count++;
String tmp = text.toString().split("\t")[1].replace(" ", "").replace("[", "").replace("]", "");
String[] arr = tmp.split(",");
int index=0;
for(int i=0;i<arr.length;i++) {
if(count==1) {
newCenters.add(Double.parseDouble(arr[i]));
}
newCenters.set(index, newCenters.get(index)+Double.parseDouble(arr[i]));
index++;
}
}
for(int i=0;i<newCenters.size();i++) {
newCenters.set(i, newCenters.get(i)/count);
}
// System.out.println("key:"+key);
context.write(key, new Text(newCenters.toString()));
// System.out.println(reducerNum);
// System.out.println("Reducer Succefully");
}
}
static class MainClass{
public static void init() throws IOException {
FileReader fr = new FileReader(new File("../../newData/part-r-00000"));
BufferedReader br = new BufferedReader(fr);
FileWriter fw = new FileWriter(new File("../../centers.txt"));
BufferedWriter bw = new BufferedWriter(fw);
String line = null;
ArrayList<String> cen = new ArrayList<>();
while((line = br.readLine()) != null) {
if(!cen.contains(line.split("\t")[1])) {
cen.add(line.split("\t")[1]);
if(cen.size()>5)break;
bw.write("\t");
bw.write(line.split("\t")[1]);
bw.newLine();
bw.flush();
}
}
bw.close();
fw.close();
br.close();
fr.close();
}
public static void run() throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// Path path = new Path("../../newDataOne");
Job job = Job.getInstance(conf);
job.setMapperClass(kmeansMapReduce.mapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(kmeansMapReduce.reducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, "../../newData/part-r-00000");
FileOutputFormat.setOutputPath(job, new Path("../../newDataOne"));
job.waitForCompletion(true);
}
public static void deletePath(String str) throws IOException {
String command = "rm -rf "+str;
Process process = Runtime.getRuntime().exec(command);
}
public static void main(String[] args) throws Exception {
init();
int cycleCount = 1;
deletePath("../../newDataOne/");
System.out.println("Cluster started:"+cycleCount);
run();
while(!kmeans.compare()) {
kmeans.copyFile();
deletePath("../../newDataOne/");
run();
cycleCount++;
System.out.println("Cluster count:"+cycleCount);
}
kmeans.copyFile();
System.out.println("Cluster Total count:"+cycleCount);
System.out.println("Cluster complete!!");
lastMapReduce.lastMainClass.main(args);
}
}
}
kmeans.java
package com.zh;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class kmeans {
public static double computerCenter(String str1, String str2) {
double upSum = 0;
double sum2arr1 = 0;
double sum2arr2 = 0;
double cos = 0;
String strr1 = str1.split("\t")[1].replace(" ", "").replace("[", "").replace("]", "");
String[] arr1 = strr1.split(",");
String strr2 = str2.split("\t")[1].replace(" ", "").replace("[", "").replace("]", "");
String[] arr2 = strr2.split(",");
for(int i=0;i<arr1.length;i++) {
upSum += (Double.parseDouble(arr1[i])*Double.parseDouble(arr2[i]));
sum2arr1 += Double.parseDouble(arr1[i])*Double.parseDouble(arr1[i]);
sum2arr2 += Double.parseDouble(arr2[i])*Double.parseDouble(arr2[i]);
}
if(upSum==0)cos=0;
else cos = upSum/(Math.sqrt(sum2arr1)*Math.sqrt(sum2arr2));
// System.out.println(cos);
return cos;
}
public static boolean compare() throws IOException {
FileReader frOld = new FileReader(new File("../../centers.txt"));
BufferedReader brOld = new BufferedReader(frOld);
FileReader frNew = new FileReader(new File("../../newDataOne/part-r-00000"));
BufferedReader brNew = new BufferedReader(frNew);
String lineOld = null;
String lineNew = null;
boolean flag = true;
while((lineOld = brOld.readLine())!=null && (lineNew = brNew.readLine())!=null) {
String old = lineOld.split("\t")[1].replace(" ", "").replace("[", "").replace("]", "");
String[] oldArr = old.split(",");
String New = lineNew.split("\t")[1].replace(" ", "").replace("[", "").replace("]", "");
String[] NewArr = New.split(",");
for(int i=0;i<oldArr.length;i++) {
if(Math.abs(Double.parseDouble(oldArr[i]) - Double.parseDouble(NewArr[i]))>0.000005) {
flag=false;
break;
}
}
break;
}
brNew.close();
frNew.close();
brOld.close();
frOld.close();
// System.out.println(oldNum+"\t"+newNum);
return flag;
}
public static void copyFile() throws Exception {
FileReader frNew = new FileReader(new File("../../newDataOne/part-r-00000"));
BufferedReader br = new BufferedReader(frNew);
FileWriter fw = new FileWriter(new File("../../centers.txt"));
BufferedWriter bw = new BufferedWriter(fw);
String line = null;
while((line = br.readLine())!=null) {
bw.write(line);
bw.newLine();
bw.flush();
}
bw.close();
fw.close();
br.close();
frNew.close();
}
}
lastMapReduce.java
package com.zh;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class lastMapReduce {
private static ArrayList<String> centers;
static class lastMapper extends Mapper<LongWritable, Text, IntWritable, Text>{
@Override
protected void setup(Mapper<LongWritable, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
FileReader fr = new FileReader(new File("../../centers.txt"));
BufferedReader br = new BufferedReader(fr);
centers = new ArrayList<>();
String line = null;
System.out.println("setup");
while((line=br.readLine()) != null) {
centers.add(line);
}
br.close();
fr.close();
}
double dis = -1;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
IntWritable num = null;
String tmp1 = value.toString();
int centersOfNum = 0;
dis = -1;
for(String str:centers) {
double dis2 = kmeans.computerCenter(tmp1, str);
if(dis2>dis) {
dis=dis2;
num = new IntWritable(centersOfNum);
}
centersOfNum++;
}
context.write(num, value);
//System.out.println("Mapper ok");
}
}
static class lastReducer extends Reducer<IntWritable, Text, IntWritable, Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> value,
Reducer<IntWritable, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
//System.out.println("Reducer");
for(Text text:value)context.write(key, text);
}
}
static class lastMainClass{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Process process = Runtime.getRuntime().exec("rm -rf ../../lastData");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(lastMapReduce.lastMapper.class);
job.setReducerClass(lastMapReduce.lastReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, "../../newData/part-r-00000");
FileOutputFormat.setOutputPath(job, new Path("../../lastData"));
job.waitForCompletion(true);
System.out.println("LastMapReducer complete!!!");
}
}
}




