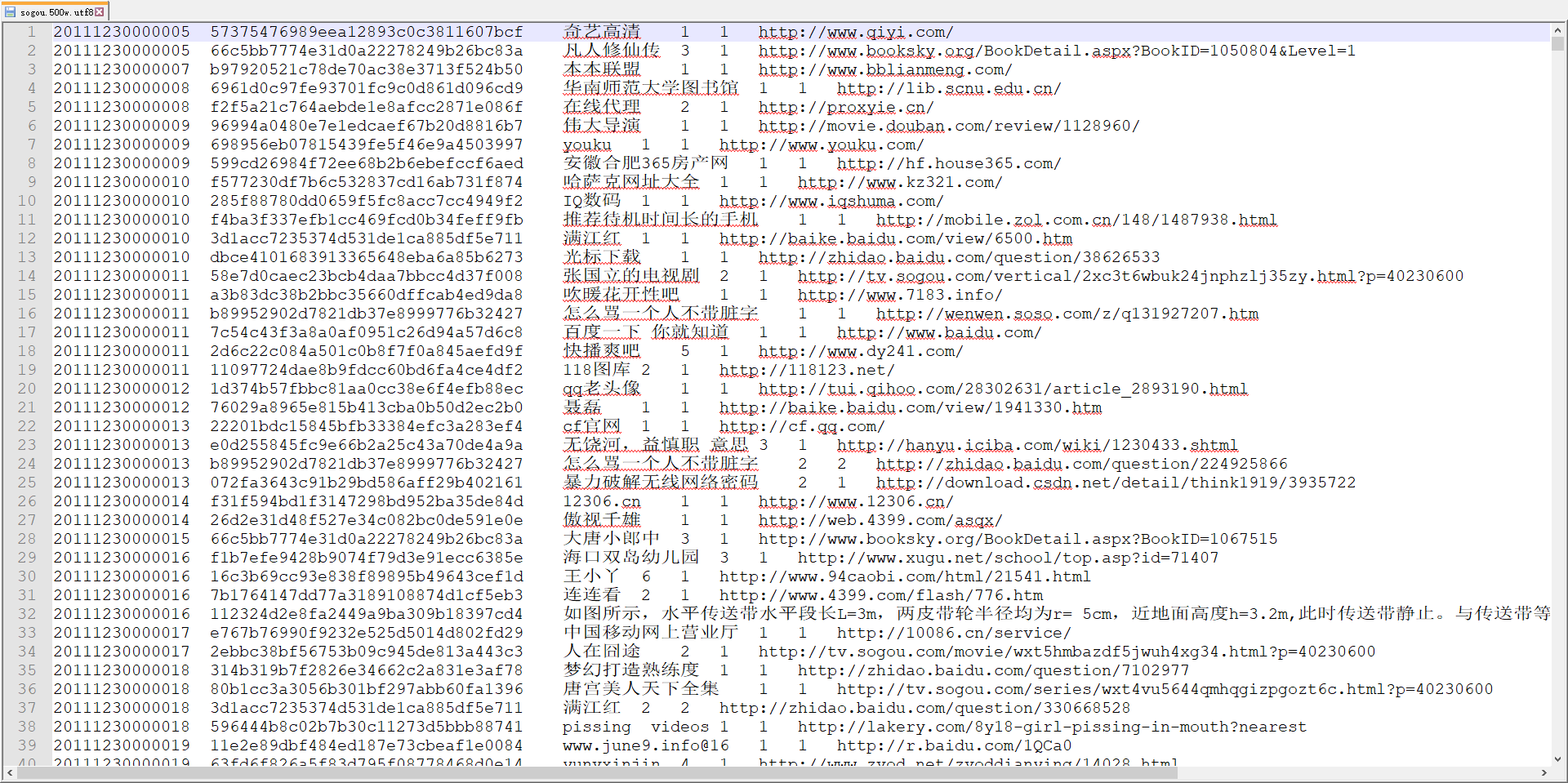
二、使用hive对数据进行统计分析
对于数据的扩展和清理工作,我是直接使用Java语言来处理,主要的代码逻辑如下:首先将元数据中的时间字段拆分出年、月、日、小时字段,并合并到元数据对应行的末尾,写入到新的文件中,然后调用清理数据的程序对扩展字段的文件进行数据检查,如果有需要清理的数据则舍弃,否则将数据写入到新的文件中。具体代码如下:
ExtData.java 扩展字段代码:
package edu.zju.bigData;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class ExtData {
public static void main(String[] args) throws IOException{
ClearData p = new ClearData();
FileReader fr = new FileReader("D:\\Desktop\\大数据技术\\sogou.full.utf8");
FileWriter fw = new FileWriter(new File("D:\\Desktop\\大数据技术\\sogou.full.utf8.ext"));
try {
String line = null;
BufferedReader br = new BufferedReader(fr);
BufferedWriter bw = new BufferedWriter(fw);
Integer count = 0;
while((line = br.readLine())!=null) {
count++;
line = line +" "+ line.substring(0, 4) +" "+ line.substring(4, 6) +" "+ line.substring(6,8) +" "+ line.substring(8, 10);
bw.write(line);
bw.newLine();
bw.flush();
}
System.out.println("ExtData Complete! total number:"+count);
bw.close();
br.close();
}catch (Exception e) {
e.printStackTrace();
}
fw.close();
fr.close();
try {
p.print();
} catch (Exception e) {
e.printStackTrace();
}
}
}
ClearData清理数据代码:
package edu.zju.bigData;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
public class ClearData {
public void print() throws Exception {
FileReader fr = new FileReader("D:\\Desktop\\大数据技术\\sogou.full.utf8.ext");
FileWriter fw = new FileWriter(new File("D:\\Desktop\\大数据技术\\sogou.full.utf8.flt"));
BufferedReader bf = new BufferedReader(fr);
BufferedWriter bw = new BufferedWriter(fw);
String line = null;
Integer count = 0;
while((line = bf.readLine())!=null) {
String[] tmp = line.trim().split("\t");
Boolean goodData = true;
if(tmp[1].isEmpty() || tmp[1].trim().isEmpty() || tmp[2].isEmpty() || tmp[2].trim().isEmpty())goodData=false;
if(goodData == true) {
count++;
bw.write(line);
bw.flush();
bw.newLine();
}else {
line = null;
tmp = null;
}
}
System.out.println("ClearData Complete! total number:"+count);
bw.close();
bf.close();
fw.close();
fr.close();
}
}
数据处理完毕后,将数据加载的HDFS上。先在集群上创建一个存放此数据的文件夹:
$ hdfs dfs -mkdir -p /sogou_ext
然后将数据上传到文件夹中:
$ hdfs dfs -put sogou.500w.utf8.flt /sogou_ext
然后,打开hive客户端:hive (未添加hive安装路径的bin路径到PATH的话,需要在hive安装位置执行 ./bin/hive 指令打开hive客户端),结果如下:
创建扩展4个字段(年、月、日、小时)数据的外部表:
create external table sogou.sogou_ext(
> ts string,
> uid string,
> keyword string,
> rank int,
> byOrder int,
> url string,
> year int,
> month int,
> day int,
> hour int
> )
> comment 'This is the sogou data of extend data'
> row format delimited
> fields terminated by '\t'
> stored as textfile
> location '/sogou_ext';
此表中的数据,即为Hadoop集群的 /sogou_ext 里面的数据。 然后在hive下创建一个带年、月、日、小时分区的表:
create external table sogou.sogou_partition(
> ts string,
> uid string,
> keyword string,
> rank int,
> byOrder int,
> url string
> )
> comment 'This is the sogou search data by partition'
> partitioned by (
> year int,
> month int,
> day int,
> hour int
> )
> row format delimited
> fields terminated by '\t'
> stored as textfile;
创建好表之后,灌入数据
hive>set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert overwrite table sogou.sogou_partition partition(year,month,day,hour) select * from sogou.sogou_ext;
然后就可以进行数据分析了。数据分析就是利用hive进行sql语句的书写,利用分布式集群来进行大数据量的快速查询,获取需要的结果,这里就给出一个例子。要分析什么全靠大家的脑洞了。
查询频度排名(频度最高的前20词):
select keyword,count(*) as cnt from sogou.sogou_ext group by keyword order by cnt desc limit 20;
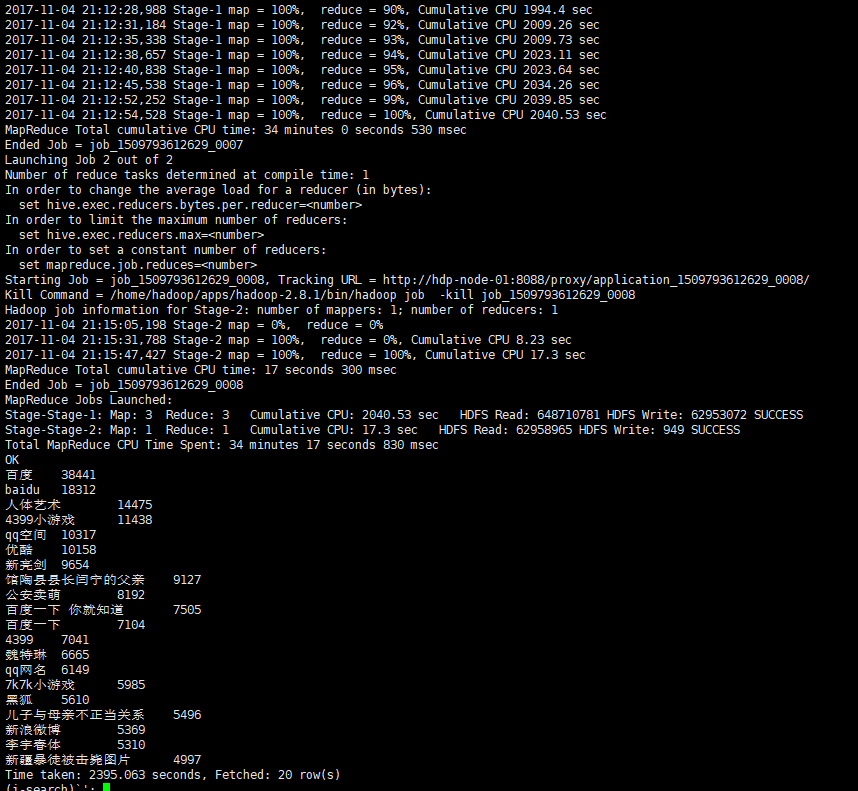
如图可知,在这次的搜索记录中,很多人都是通过sogou这一平台来访问baidu平台的,很有可能是使用的浏览器默认打开的页面是sogou。并且4399小游戏的搜索记录占比也很大,说明这次搜索记录中有可能是小孩子的搜索次数很多。
到此Sogou数据分析的内容就结束了,如果有错误欢迎指正,一起进步。最后附上本次的数据源格式: