
Python分析《冰与火之歌》
本次数据爬取的是小说《冰与火之歌》,代码方面采用Python语言对小说进行文本获取。使用了python的jieba分词和wordcloud实现。jieba分词,最好用的开源中文分词工具,他最主要的两个功能是分词和关键词的抽取,在我们这次的任务中,我们使用了关键词抽取的功能,用他的分词功能来提取文本中的人名。在数据可视化方面,采用gephi,我们把数据处理成gephi可接受的csv格式,然后进行绘制可视化图形。
冰与火之歌网络图分析
一、代码原理
这个代码的实现原理是基于简单的共现关系,利用Python代码从纯文本中提取出人物关系网络,并用Gephi将其生成的网络可视化。那么什么是共现原理呢?实体间的共现是一种基于统计的信息提取。关系紧密的人物往往会在文本中多段内同时出现,可以通过识别文本中已确定的实体(如此次的人名,家族名),计算不同实体间共同出现的次数和比率。当比率大于某一阈值,我们认为两个实体间存在某种联系。
二、数据处理方式
在词云中,我们只能通过词的大小来了解该词对于文本集是否起关键作用,无法探究人物之间的关系,而在关系网图中,不仅可以了解词的关键程度,还能发现人物之间的联系。所以,绘制词云的时候,我们只需要提取两列数据,一列人名,一列为频率。而绘制网络图时,就需要两组数据。网络图都是由节点和边构成的,节点数据也就是节点值+权值,边数据就是出度+入度+权重。
对应到文本的例子中来,绘制《冰与火之歌》中的关系图,具体的处理方式如下:
1.对文本进行针对性分词,统计人物(家族)在文本中的出场次数。
2.以段落为单位进行划分,统计每段中的人物(家族),两两配对后计数,形成粗略的人物(家族)关系统计。
3.生成的数据保存为gephi可以读取的csv格式,人物(家族)出场次数输出格式为(Id,Lable,Weight),关系输出格式为(Source,Target,Weigh),即节点数据和边数据。
但是由于《冰与火之歌》这系列好几卷的小说中,有些人物是有一些绰号的,人物之前的称呼有可能不是直呼名字,所以还需要一个别名的字典来减少一些误差。这样做结果虽然依旧是粗略的,但是通过对文本的理解,绘制的图还是有一定的参考意义的。
三、实现流程
代码实现主要分为三个部分:1.人物出场次数的统计。2.人物关系的统计。3.格式化输出。
因为要利用代码提取出我们需要的人名或者家族名,所以,首先我们需要准备对应的字典,用于分词。
文本人物(家族)字典
由于《冰与火之歌》这5卷小说中,不包括动物在内,出现的人名据统计高达1800+,我们自然没有办法全部罗列出,所以我们选取了100个左右的最为核心的人物角色,也是电视剧权力的游戏中让我们印象比较深的人物角色来进行分析。我们从维基百科等地方找出本小说中最为关键的前100个人物,并在小说文本中搜索以确保此翻译存在且准确,将主要人物名称保存在dict.csv文件中。同样的,家族数据通过同样的方式保存到family.csv文件中。
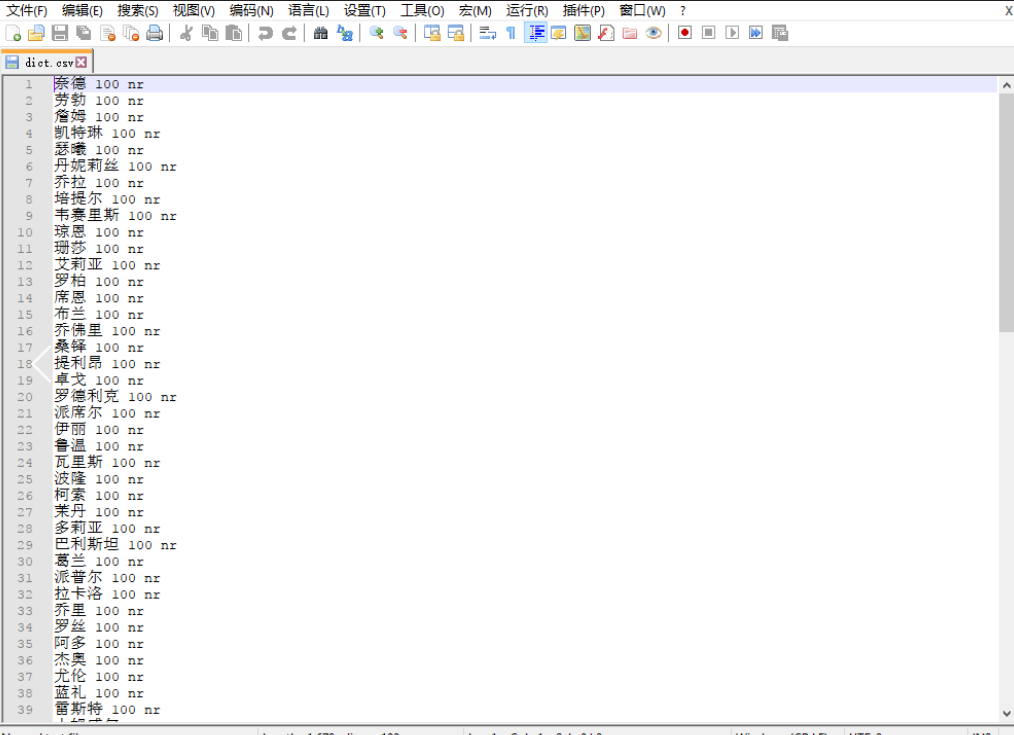
其中第一个参数值即人物名称,第二个参数为权重增量,第三个为名词属性的意思,即人名。
家族方面,主要提取了关键的大家族,数据如下:
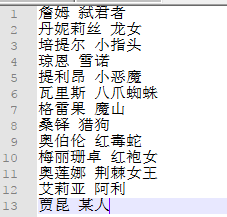
人物别称映射字典
这部小说中有很多角色会有不同的别称,所以需要一个映射字典,将不同的称呼都映射到同一个人名当中。我们同样通过网络获取所能知道的人物别名,并在小说文本中确认是否准确。
具体代码解释
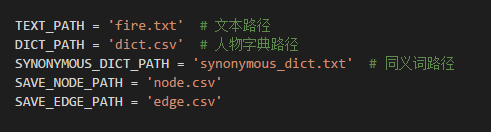
定义文件路径常量和初始化全局变量:
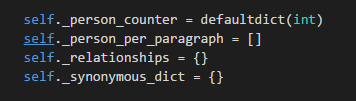
其中:
person_counter是一个计数器,用来统计人物(家族)出现的次数。
person_per_paragraph为每段文字中出现的人物,形如[[‘a’,’b’],[]]的列表
relationships保存的是人物间的关系。是一个字典,key为人物,value为包含人物和权值的字典。
synonymous_dict为别名字典。
经过人物出场次数统计、人物关系统计、格式化输出后得到以下输出结果:
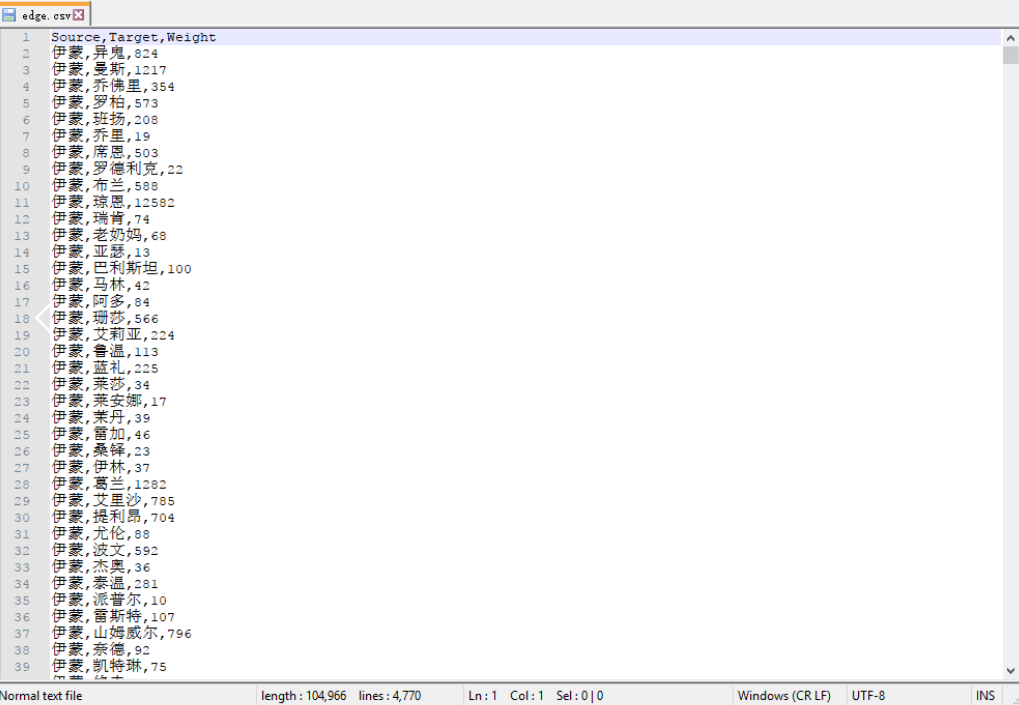
edge.csv 边数据:
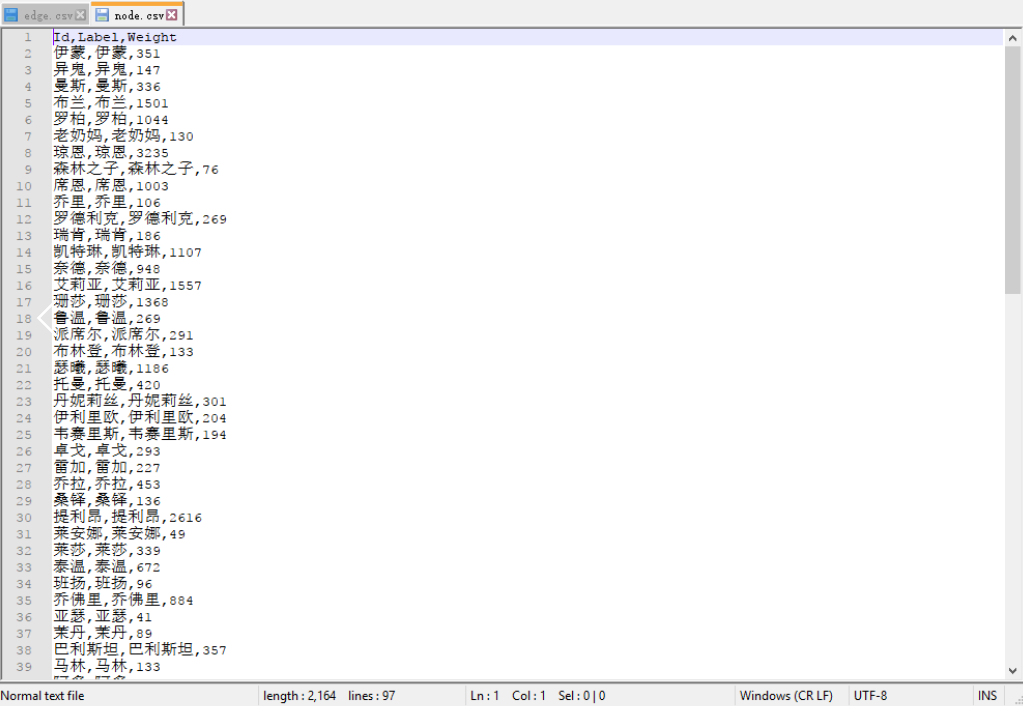
node.csv 节点数据
获取这些数据之后,就可以利用Gephi来进行数据可视化分析了。
冰与火之歌Gephi分析
下面进行Gephi的简单的使用介绍
Gephi使用步骤
- 添加节点表格和边表格
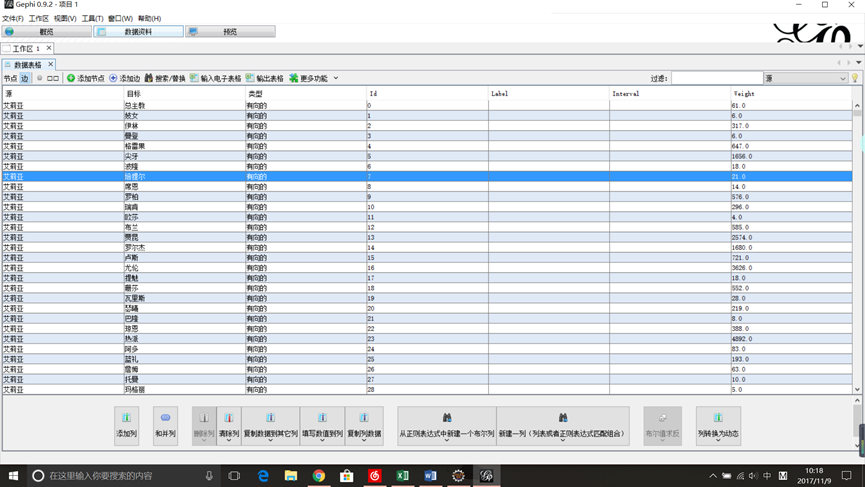
如上图,新建项目后,点击数据资料这一选项,然后在左上角“数据表格”栏下的“节点 边”选项中选择“边”,然后点击“输入电子表格”,将我们上面代码生成的csv边数据文件作为输入,然后在弹出的界面中选择合适的分隔符,字符集等选项以保证数据导入正确,时间设定默认,导入的列三列都选上,Weight下选Double项,然后点击完成,会弹出一个输入报告,这里因为生成的数据是有向的格式,所有“图的类型”要选择“有向的”或者是“混合的”,选“无向的”会只有点而没有变显示。(如果要生成无向图数据,需要将输出加入一个”Undirected”字段)其他可以不动。完成后便能得到上图界面。我们可以在“节点”那,如果Label栏没有数据,那么生成的图将没有标签,我们可以在下面一列选项中选择“复制数据到其他列”选项,选择复制Id列,在弹出来的窗口中选Label项。这样生成的图就能够显示节点名称了,如果点击显示标签会乱码的话,将字体改成中文的字体就可以了。
- 图形处理
在“概览”界面我们可以看到生成的图形,如下图,当然一开始图形很难看,需要设置一些参数,使其变好看。我们可以在左边“外观”这一栏中选择“节点”选项,它右边有四个图标,分别代表:节点颜色、节点大小、标签颜色、标签大小,我们选节点颜色,选“Ranking”以“连入度”为标准来设置,颜色条右边一点有个小图标可以选择渐变的颜色,其他的设置都大致类似,不再赘述。下面的“布局”栏可以选择一些布局方式。
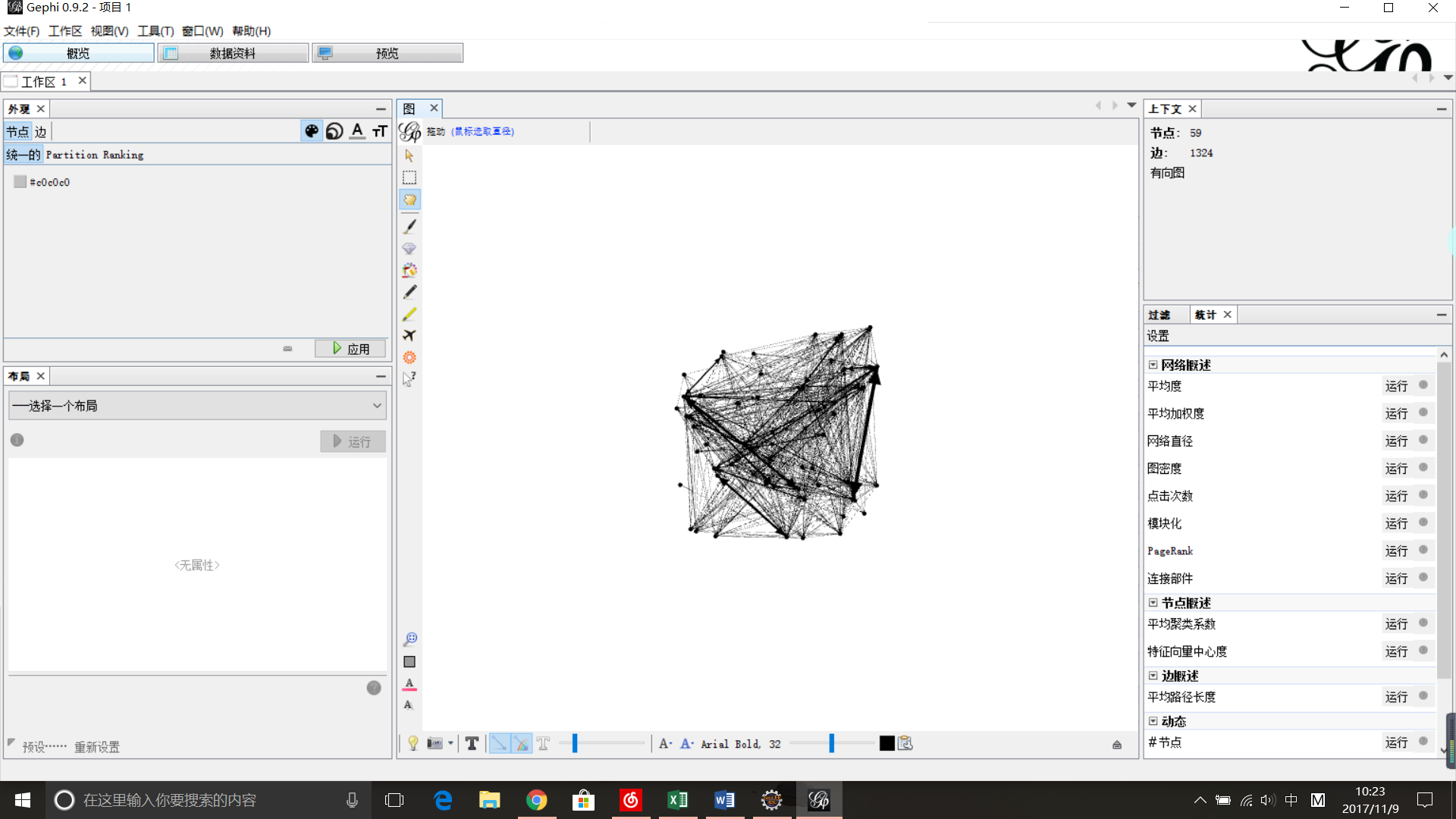
当然,想要图像变得好看,可以在“概览”中不断调节以下几个部分的参数,查看动态效果图:
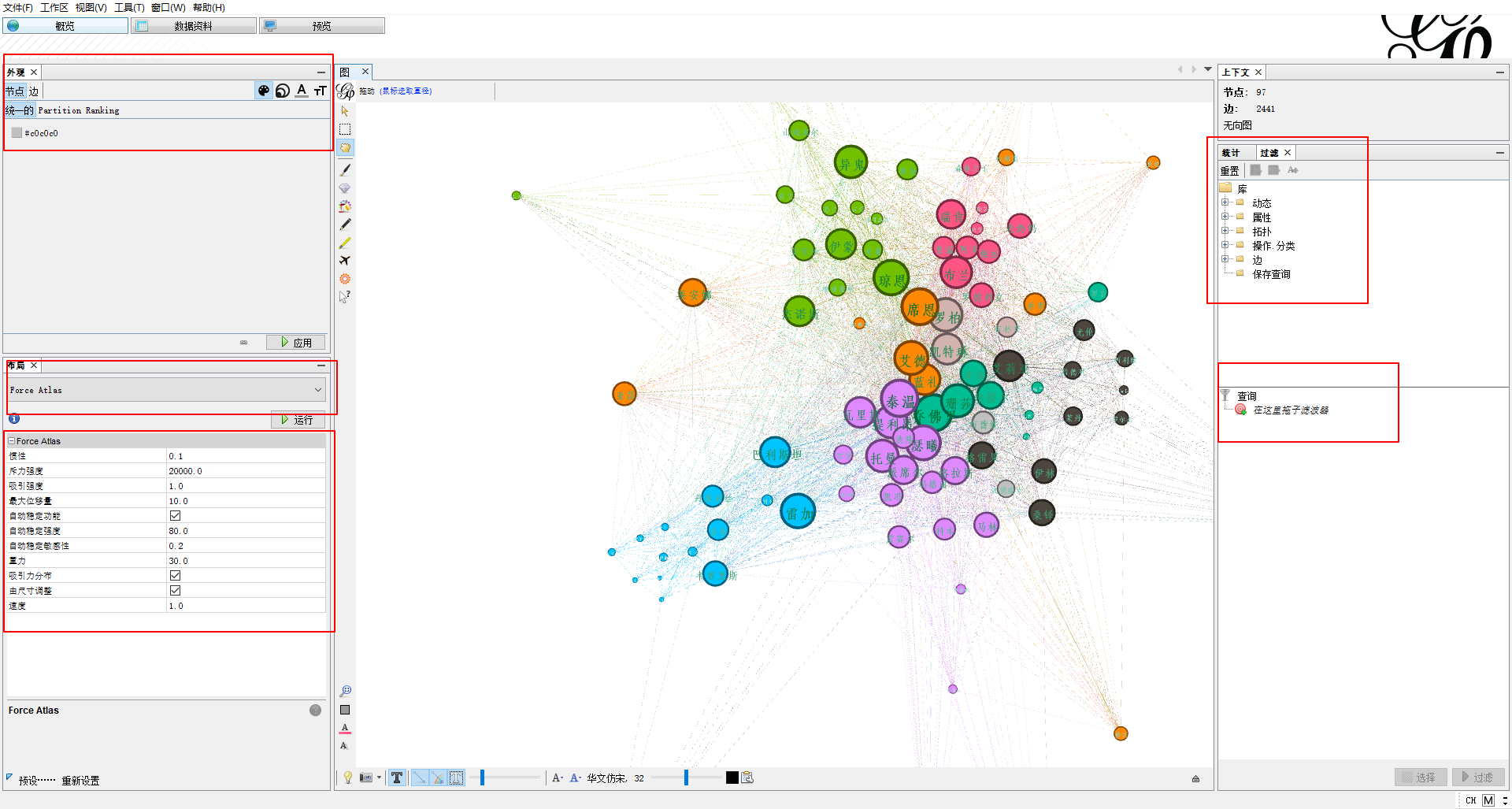
也可以在“预览”界面主要调节以下几个参数,来看静态的效果图:
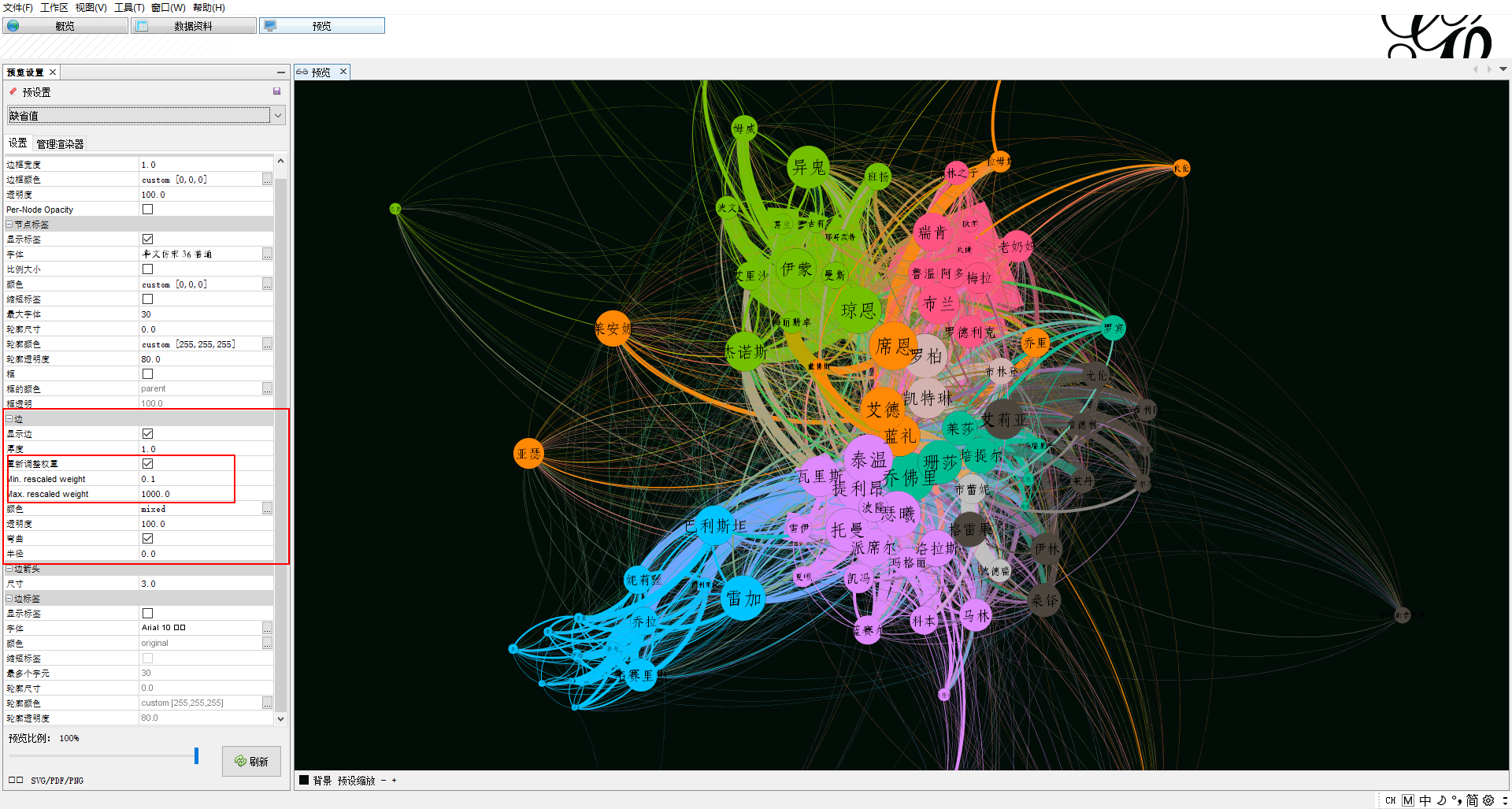
当然,也可以使用统计工具来获取图数据的一些信息:
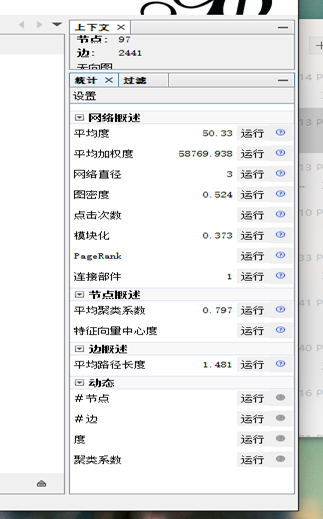
比如上图的统计信息中,网络直径为3,说明这部小说中,不管多么微小的人物,多么不相干的人物,都可以通过大约3个人就能建立起联系,不过因为选取角色的时候只选择了最为重要的百来个角色,所以网络直径比较小。
结果展示
下面展示几个Gephi分析效果图:

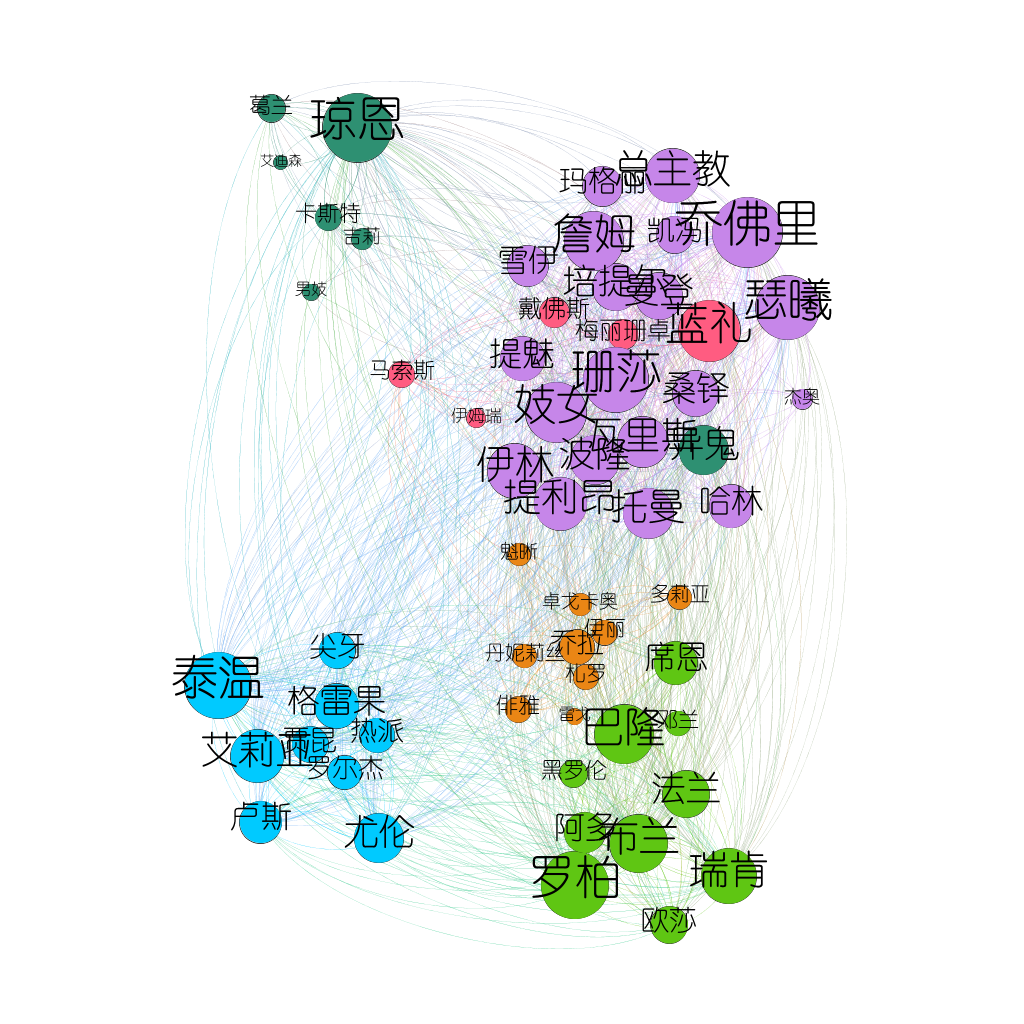
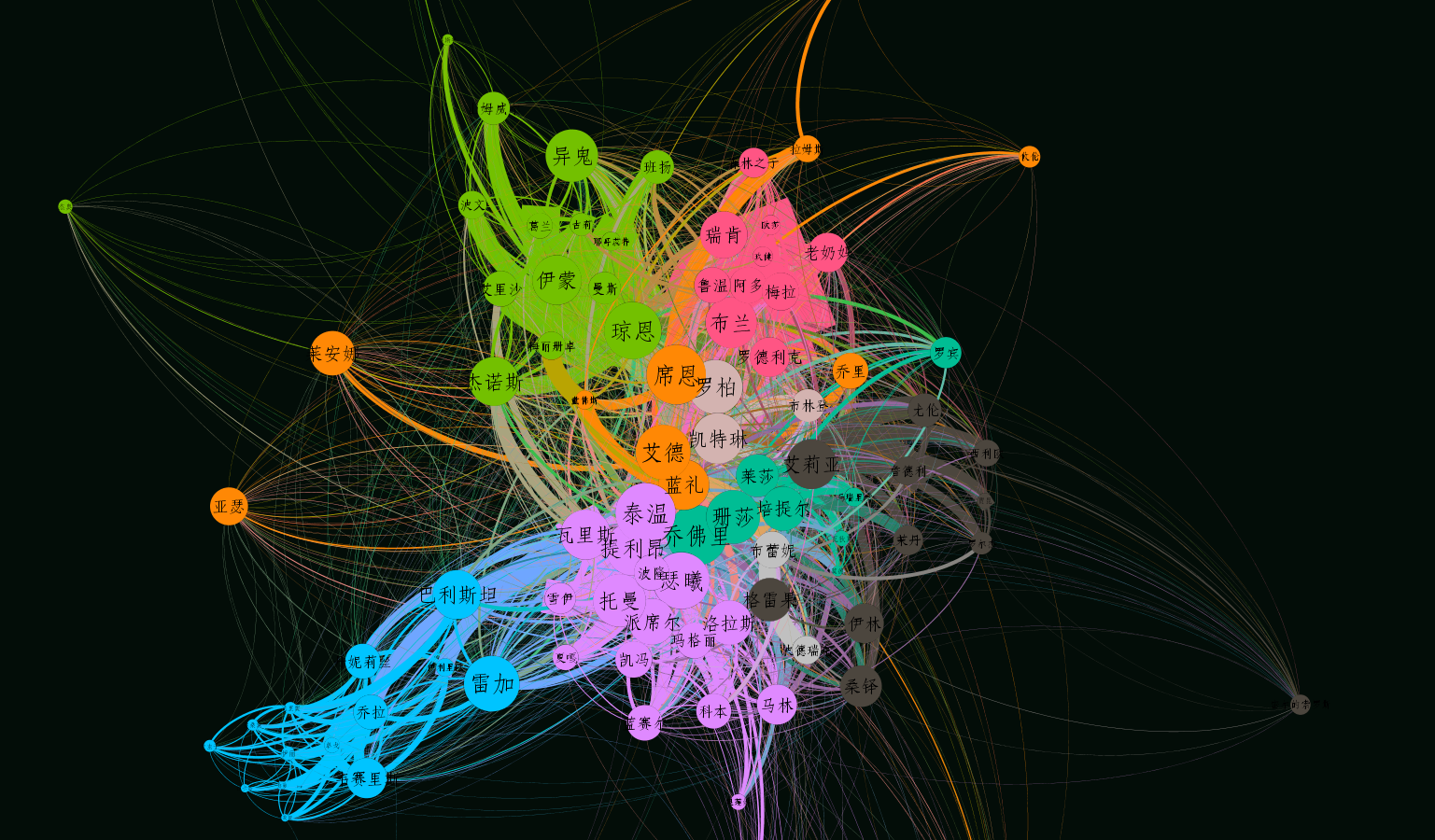
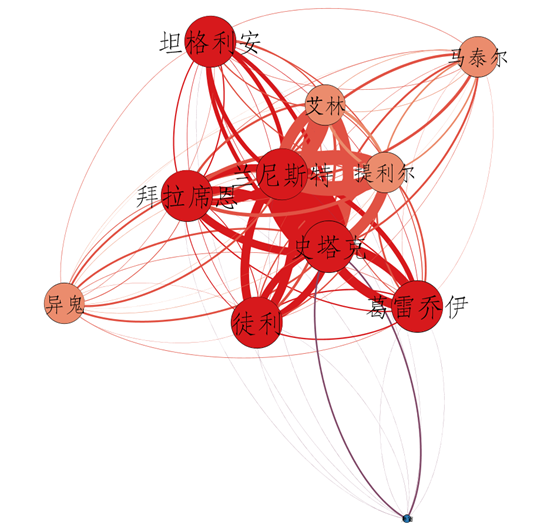
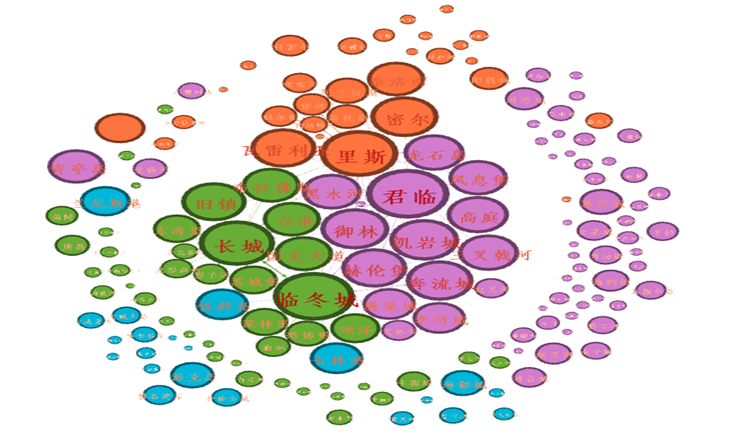
至此,本次Gephi数据可视化分享到此结束,如有错误或不足之处欢迎批评指正。
附录
这个代码虽然很多地方都有源码,不过这里还是直接给出,方便大家讨论:
# -*- coding: utf-8 -*-
from __future__ import print_function
import jieba
import codecs
from collections import defaultdict
TEXT_PATH = 'fire.txt' # 文本路径
DICT_PATH = 'dict.csv' # 人物字典路径
SYNONYMOUS_DICT_PATH = 'synonymous_dict.txt' # 同义词路径
SAVE_NODE_PATH = 'node.csv'
SAVE_EDGE_PATH = 'edge.csv'
class RelationshipView:
def __init__(self, text_path, dict_path, synonymous_dict_path):
self._text_path = text_path
self._dict_path = dict_path
self._synonymous_dict_path = synonymous_dict_path
'''
person_counter是一个计数器,用来统计人物出现的次数。{'a':1,'b':2}
person_per_paragraph每段文字中出现的人物[['a','b'],[]]
relationships保存的是人物间的关系。key为人物A,value为字典,包含人物B和权值。
'''
self._person_counter = defaultdict(int)
self._person_per_paragraph = []
self._relationships = {}
self._synonymous_dict = {}
def generate(self):
self.count_person()
self.calc_relationship()
self.save_node_and_edge()
def synonymous_names(self):
'''
获取同义名字典
:return:
'''
with codecs.open(self._synonymous_dict_path, 'r', 'utf-8') as f:
lines = f.read().split('\r\n')
#print(lines);
for l in lines:
self._synonymous_dict[l.split(' ')[1]] = l.split(' ')[0]
return self._synonymous_dict
def get_clean_paragraphs(self):
'''
以段为单位分割全文
:return:
'''
with codecs.open(self._text_path, 'r', 'utf-8') as f:
paragraphs = f.read().split('\r\n\r\n')
#print(paragraphs)
#print(len(paragraphs))
return paragraphs
def count_person(self):
'''
统计人物出场次数,添加每段的人物
:return:
'''
paragraphs = self.get_clean_paragraphs()
synonymous = self.synonymous_names()
#print('start process node')
with codecs.open(self._dict_path, 'r', 'utf-8') as f:
name_list = f.read().split(' 100 nr\r\n') # 获取干净的name_list
#print(name_list)
for p in paragraphs:
jieba.load_userdict(self._dict_path)
# 分词,为每一段初始化新字典
poss = jieba.cut(p)
self._person_per_paragraph.append([])
for w in poss:
# 判断是否在姓名字典以及同义词区分
if w not in name_list:
continue
if synonymous.get(w):
w = synonymous[w]
# 往每段中添加人物
self._person_per_paragraph[-1].append(w)
# 初始化人物关系,计数
if self._person_counter.get(w) is None:
self._relationships[w] = {}
self._person_counter[w] += 1
return self._person_counter
def calc_relationship(self):
'''
统计人物关系权值
:return:
'''
print("start to process edge")
for p in self._person_per_paragraph:
for name1 in p:
for name2 in p:
if name1 == name2:
continue
if self._relationships[name1].get(name2) is None:
self._relationships[name1][name2] = 1
else:
self._relationships[name1][name2] += 1
return self._relationships
def save_node_and_edge(self):
'''
根据dephi格式保存为csv
:return:
'''
with codecs.open(SAVE_NODE_PATH, "w+", "utf-8") as f:
f.write("Id,Label,Weight\r\n")
for name, times in self._person_counter.items():
f.write(name + "," + name + "," + str(times) + "\r\n")
with codecs.open(SAVE_EDGE_PATH, "w+", "utf-8") as f:
f.write("Source,Target,Weight\r\n")
for name, edges in self._relationships.items():
for v, w in edges.items():
if w > 3:
f.write(name + "," + v + "," + str(w) + "\r\n")
#f.write(name + "," + v + "," + str(w) + "," + "Undirected" + "\r\n") 此为生成无向图的数据代码
print('save file successful!')
if __name__ == '__main__':
v = RelationshipView(TEXT_PATH, DICT_PATH, SYNONYMOUS_DICT_PATH)
v.generate()
小伙伴有弄《冰与火之歌》的词云分析,我虽然没贴其内容,但这里也将其代码贴出:
# -*- coding: utf-8 -*-
from __future__ import print_function
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud
jieba.load_userdict("namedict.csv")
# 设置相关的文件路径
bg_image_path = "./pic/image.jpg"
text_path = './byhzg_1.txt'
font_path = 'msyh.ttf'
stopwords_path = './stopword.txt'
def clean_using_stopword(text):
"""
去除停顿词,利用常见停顿词表+自建词库
:param text:
:return:
"""
mywordlist = []
seg_list = jieba.cut(text, cut_all=False)
liststr = "/".join(seg_list)
with open(stopwords_path,'r',encoding="utf-8") as f_stop:
f_stop_text = f_stop.read()
#f_stop_text = str(f_stop_text)
f_stop_seg_list = f_stop_text.split('\n')
for myword in liststr.split('/'): # 去除停顿词,生成新文档
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ''.join(mywordlist)
def preprocessing():
"""
文本预处理
:return:
"""
with open(text_path,'rb') as f:
content = f.read()
return clean_using_stopword(content)
return content
def extract_keywords():
"""
利用jieba来进行中文分词。
analyse.extract_tags采用TF-IDF算法进行关键词的提取。
:return:
"""
# 抽取1000个关键词,带权重,后面需要根据权重来生成词云
allow_pos = ('nr',) # 词性
tags = jieba.analyse.extract_tags(preprocessing(), 1500, withWeight=True)
keywords = dict()
for i in tags:
print("%s---%f" % (i[0], i[1]))
keywords[i[0]] = i[1]
'''
with open("namedict.csv","rb") as f:
line=f.readline()
if line == i[0]:
keywords[i[0]] = i[1]
'''
return keywords
def draw_wordcloud():
"""
生成词云。1.配置WordCloud。2.plt进行显示
:return:
"""
back_coloring = plt.imread(bg_image_path) # 设置背景图片
# 设置词云属性
wc = WordCloud(font_path=font_path, # 设置字体
background_color="white", # 背景颜色
max_words=2000, # 词云显示的最大词数
mask=back_coloring, # 设置背景图片
)
# 根据频率生成词云
wc.generate_from_frequencies(extract_keywords())
# 显示图片
plt.figure()
plt.imshow(wc)
plt.axis("off")
plt.show()
# 保存到本地
wc.to_file("./wordcloud.jpg")
if __name__ == '__main__':
draw_wordcloud()




