
前言
首先,为什么会有这篇学习记录呢?因为之前的聚类分析使用这种方式去聚类是比较好的一种方式,但是当时没有用,所以现在来了解一下这个算法。网络上其实不乏好的TF-IDF算法入门博客,这里也只是记录下我所了解到的知识。
基本概念
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文件频率)算法是很常见的一种入门级机器学习算法,是属于自然语言处理中的一类。是一种用于查询信息与信息归类的一种使用比较频繁的加权技术。TF-IDF是一种统计方法,用来评估一个字词或者短语在文本中的重要程度。字词或者短语的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎引用,作为文件与用户查询之间相关程度的度量或评级。
想要进行信息检索、文本分类等操作,首先需要知道一个文本的关键词或短语是哪些,然后依据这些来进行分类等操作,而计算机进行关键词的提取这个问题涉及到了数据挖掘、文本处理、信息检索等多个计算机的前沿领域,学习起来过于晦涩难懂,但是可以通过相对简单的TF-IDF算法来实现这个目的。
拿上次的Gephi数据可视化博客来作为例子,分析《冰与火之歌》文本中的人物关系,如果某个角色名称出现的次数最多,那么它便是这部小说的关键人物。但是,一般来说,出现次数最多的词是“的”、“是”、“在”等这一类最常用的词。它们叫做“停用词”(stop words),它们出现的次数很高,但是结果却毫无意义、所以必须过滤掉。现在我们假设把这一类词都过滤了,只考虑有实际意义的词,那么有可能出现“琼恩”、“龙母”、“君临”等词汇出现的次数一样多,但是“君临”作为一个地点词,在关键词当中,它们的重要性是不一样的,所以我们需要对关键词做一些关于重要性的系数的一些调整,以便于判断一个词或短语是不是常见词。如果某个词或短语比较少见,但是它在这篇文章中出现的次数比较多,那么它就很有可能反映了这篇文章的特性,这才是我们要找的关键词。下面是TF-IDF的具体概念和计算步骤:
第一步 计算词频
在文本中,词频(Term Frequency,TF),指的是我们筛选或经过分词而给出的词或短语在这个文本里出现的次数。考虑到有的文章长,有的文章短,有时候会有一个词语在比较短的文章出现的次数少于在比较长的文章中出现的次数,所以一般都会进行词频处于这篇文章总词数的归一化处理,为了便于不同文章的比较,进行词频的标准化处理,就可以得到下面的公式表示词或短语的重要性:

第二步 计算逆文档频率
逆向文档频率(Inverse Document Frequency,IDF),是一个词语普遍重要性的度量。其主要的思想是:如果文本资料中包含词或短语T的次数越少,但是这个词或短语的IDF越大,那么就说明该词或短语具有很好的区分文本类型的能力。一个词或者短语的IDF,可以通过总的文本内容除以文本中包含该词或短语的数目,再将得到的结果取对数得到。利用统计方法来解释的话,就是在获取的词频数据的基础上,对每个词或短语赋予一个“重要性”的权重。最常见的词语(如“的”、“是”、“在”等)给这些词以最低权重,较少见的词赋予较大的权重。这个权重就是IDF,它的大小与一个词的常见程度成反比,计算公式如下:
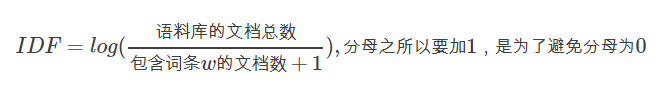
如果出现一个词或短语的频率越高,并且分母越大,逆文档频率就越小越接近0。
第三步 计算TF-IDF
解释完了TF和IDF的概念之后,那么TF-IDF的主要思想是:如果某个词或短语在一个文本中出现的频率TF很高,但是这个词或短语在其他的文章中出现的次数却不多,那么就可以认为该词或者短语拥有很好的区分文本类型的能力,比较适合用来进行聚类分析。TF-IDF实际上是如下公式:
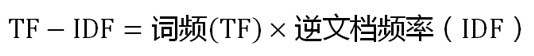
从上面的公式中可以看到,TF-IDF是文本中高词语频率,以及该词语在整个文本集合中的低文件频率的乘积,与词或短语在文本中出现的次数成正比,与该词或短语在全部文本中出现的次数成反比。所以,自动提取关键词的算法就很清楚了,就是经过分词后,然后计算出文本中的每个词或短语的TF-IDF值,然后按降序排列,取排在最前面的几个词。
应用
IF-IDF经常和“余弦相似度”相结合来进行相似度的比较。首先需要对文本进行分词,那么如何进行“余弦相似度”的求解,以一个简单的例子来说明:
句子A:浙江大学软件学院大数据技术 </br>
句子B:浙江大学软件学院软件工程大数据分析 </br>
现在我们如何判断上面的两个句子是否属于相似的文本,基本的思路是:如果组成这两个句子的词或者短语相同的越多,说明他们想表达的内容就应该越相近。因此,我们可以从组成文本的词或者短语着手,来判断它们是否相似。
首先,将句子分词:
句子A:浙江/大学/软件/学院/大/数据/技术</br>
句子B:浙江/大学/软件/学院/软件/工程/大/数据/分析</br>
再次,计算词频:
句A:浙江 1,大学 1,软件 1,学院 1,工程 0,大 1,数据 1,技术 1,分析 0
句B:浙江 1,大学 1,软件 2,学院 1,工程 1,大 1,数据 1,技术 0,分析 1
最后,写出词频向量:
句A:[1,1,1,1,0,1,1,1,0] </br>
句B:[1,1,2,1,1,1,1,0,1] </br>
获取到了文本的词频矢量后,问题就可以从如何计算文本相似度转变为如何计算词或者短语的矢量的相似度了,有了这些矢量数据后就可以利用“余弦相似度”原理来进行计算。我们可以把词频矢量想象成空间中的线段,都是从原点([0,0,…])出发,指向不同方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向完全相反。因此,我们可以通过夹角的大小,来判断矢量之间的相似程度。夹角越小,就代表越相似。假定两个线段的矢量分别是a[x1,y1],b[x2,y2],那么根据余弦定理可以得到如下公式:
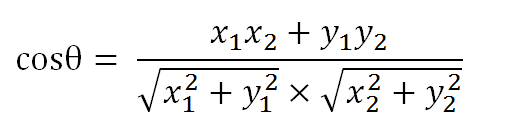
并且,余弦的这种计算方法对多维向量也成立,也就是说假定A和B是两个n维向量,A是[A1,A2,A3,…,An],B是[B1,B2,B3,…,Bn],则A与B的夹角θ的余弦等于:
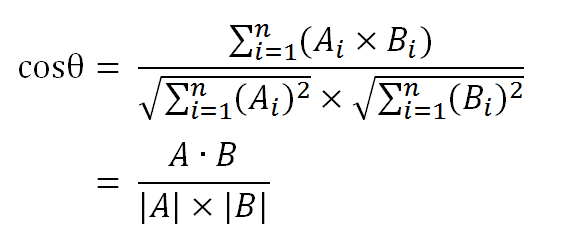
这样就可以得到两个矢量的余弦值,余弦值越接近1,就表明夹角越接近0度,也就是两个矢量越相似。由此,可以总结出一种聚类算法:
-
将文本进行分词,使用TF-IDF算法,找出不同文本的关键词
-
每个文本各取出若干关键词,合并成一个集合,计算每个文本对于这个集合的词或短语的词频
-
生成文本各自的词频矢量
-
计算两个矢量的余弦相似度,值越大就表示越相似
之前的搜狗搜索数据聚类分析,就可以先将每一条记录都计算出他的TF-IDF值,然后根据每条搜索记录的TF-IDF数值来作为判断搜索记录之间相似度的依据来进行聚类操作。这样先将每条记录的TF-IDF值算出来,然后在根据其进行聚类的方法可以在每次mapreduce迭代的时候计算量减少很多。
### TF-IDF的优点以及不足之处
TF-IDF算法的优点是简单易懂,且比较好上手,所获得的结果也比较准确。但是TF-IDF算法是基于这样一个假想之上:区分文本是否相似应该是拿在文本中出现次数最多的并且有意义的词或短语,但是在整个文本集合的其他文本中出现次数少的词或短语,所以如果词频作为判断依据,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,TF-IDF算法认为一个单词出现的文本次数越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度IDF的概念,以TF和IDF的乘积作为空间坐标系的取值测度,并用它完成对权值TF的调整,调整权值的目的在于突出重要单词,抑制次要单词。但是本质上IDF是一种试图抑制噪声的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用,显然这并不是完全正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以TF-IDF算法的精度并不是很高。此外,在TF-IDF算法中并没有体现单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中对文章内容的反映程度不同,其权重的计算方法也应不同。因此在对于网页的文档进行分析的时候,应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示的效果。
在深入一点分析,有时候数据集合中关于类别的分布往往是偏斜(Skewed)的,也就是说不同类别的文档数会存在很大数量上的差别,而这些差别十分影响TF-IDF的权重计算结果。这是因为IDF在计算特征项权重的时候是以总文本数作为基准的,当总文本集合中类别分布太不均匀的时候,IDF的抑制作用基本不起效果。所以TF-IDF不能折中TF和IDF两个的结果,导致该特征项权重只是一味的依赖词频TF,这样就会导致结果错误。所以Bong Chih How和Narayanan K提出了使用 Category Term Descriptor(CTD)来改进TF-IDF算法,来弥补类别数据集偏斜带来的问题。公式如下:
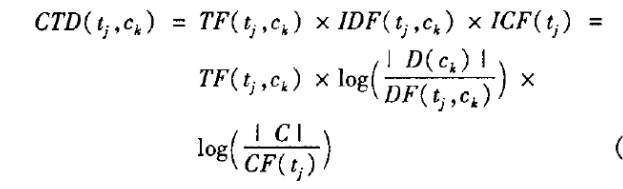
其中 TF指特征项t¬j在类ck中出现的次数;D(ck)指类别ck中的文档数,DF(tj,ck)指类别ck中出现特征项tj的文档数;C代表类别数,CF(tj,ck)指出现特征项tj的类别数。
当然,这些都是后话了,基本的TF-IDF的大体内容就学到此,这篇博文也是看了一些其他人的文章后记录的,大体内容或许很相近,不过能学到知识就是好事。如果什么不妥请联系我。




